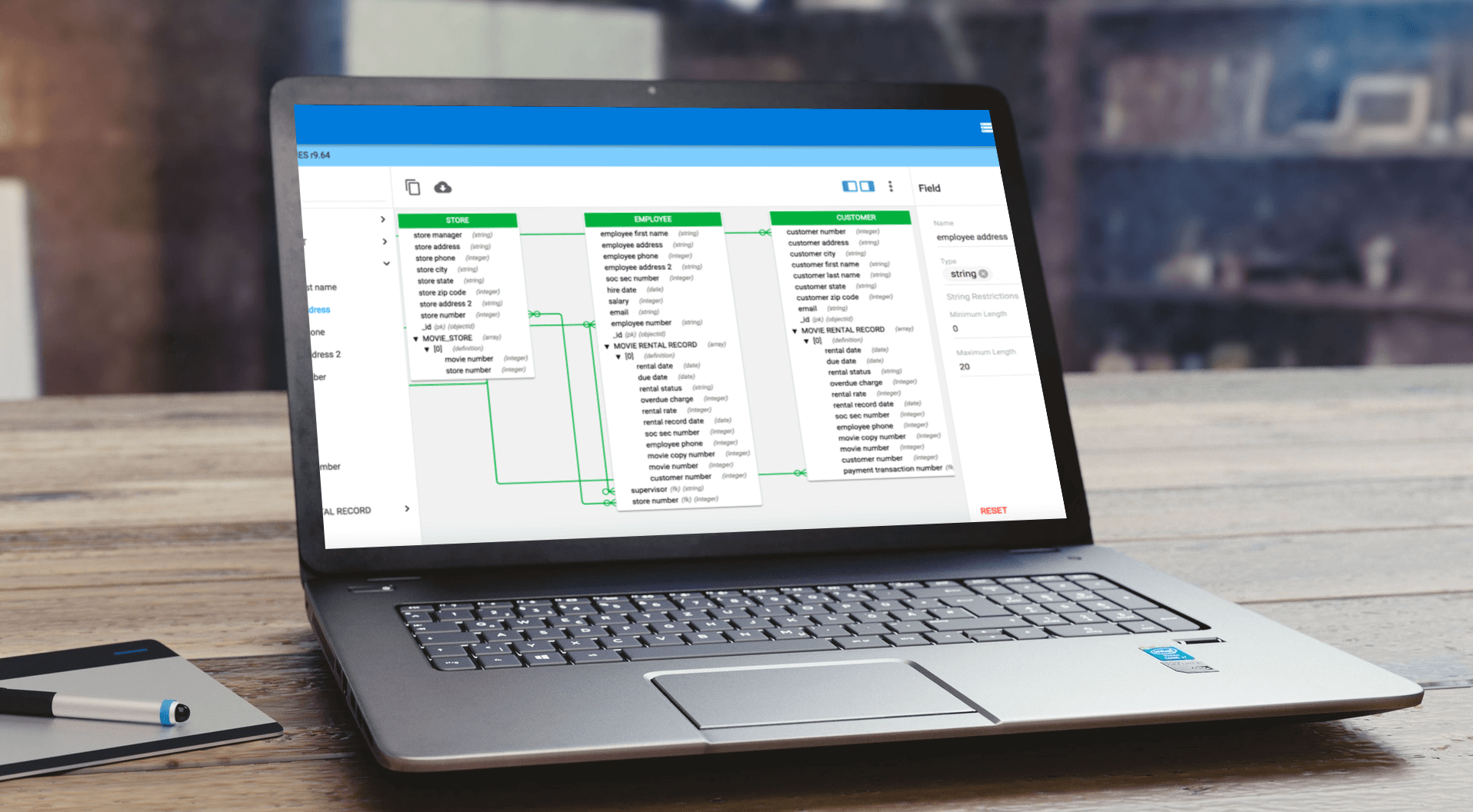
A common question in the modern data management space involves database technology: SQL, NoSQL or NewSQL?
But there isn’t a one-size-fits-all answer. What’s “right” must be evaluated on a case-by-case basis and is dependent on data maturity.
For example, a large bookstore chain with a big-data initiative would be stifled by a SQL database. The advantages that could be gained from analyzing social media data (for popular books, consumer buying habits) couldn’t be realized effectively through sequential analysis. There’s too much data involved in this approach, with too many threads to follow.
However, an independent bookstore isn’t necessarily bound to a big-data approach because it may not have a mature data strategy. It might not have ventured beyond digitizing customer records, and a SQL database is sufficient for that work.
Having said that, the “SQL, NoSQL or NewSQL” question is gaining prominence because businesses are becoming increasingly data-driven.
In 2019, an IDC study found 85% of enterprise decision-makers said they had a time frame of two years to make significant inroads into digital transformation or they will fall behind their competitors and suffer financially. Furthermore, a Progress study showed that 85% of enterprise decision-makers feel they only have two years to make significant digital-transformation progress before suffering financially and/or falling behind competitors.
Considering these statistics, what better time than now to evaluate your database technology? The “SQL, NoSQL or NewSQL question,” is especially important if you intend to become more data-driven.
SQL, NoSQL or NewSQL: Advantages and Disadvantages
SQL
SQL databases are tried and tested, proven to work on disks using interfaces with which businesses are already familiar.
As the longest-standing type of database, plenty of SQL options are available. This competitive market means you’ll likely find what you’re looking for at affordable prices.
Additionally, businesses in the earlier stages of data maturity are more likely to have a SQL database at work already, meaning no new investments need to be made.
However in the modern digital business context, SQL databases weren’t made to support the the three Vs of data. The volume is too high, the variety of sources is too vast, and the velocity (speed at which the data must be processed) is too great to be analyzed in sequence.
Furthermore, the foundational, legacy IT world they were purpose-built to serve has evolved. Now, corporate IT departments must be agile, and their databases must be agile and scalable to match.
NoSQL
Despite its name, “NoSQL” doesn’t mean the complete absence of the SQL database approach. Rather, it works as more of a hybrid. The term is a contraction of “not only SQL.”
So, in addition to the advantage of continuity that staying with SQL offers, NoSQL enjoys many of the benefits of SQL databases.
The key difference is that NoSQL databases were developed with modern IT in mind. They are scalable, agile and purpose-built to deal with disparate, high-volume data.
Hence, data is typically more readily available and can be changed, stored or handle the insertion of new data more easily.
For example, MongoDB, one of the key players in the NoSQL world, uses JavaScript Object Notation (JSON). As the company explains, “A JSON database returns query results that can be easily parsed, with little or no transformation.” The open, human- and machine-readable standard facilitates data interchange and can store records, “just as tables and rows store records in a relational database.”
Generally, NoSQL databases are better equipped to deal with other non-relational data too. As well as JSON, NoSQL supports log messages, XML and unstructured documents. This support avoids the lethargic “schema-on-write,” opting to “schema-on-read” instead.
NewSQL
NewSQL refers to databases based on the relational (SQL) database and SQL query language. In an attempt to solve some of the problems of SQL, the likes of VoltDB and others take a best-of-both-worlds approach, marrying the familiarity of SQL with the scalability and agile enablement of NoSQL.
However, as with most seemingly win-win opportunities, NewSQL isn’t without its caveats. These vary from vendor to vendor, but in essence, you either have to sacrifice familiarity side or scalability.
If you’d like to speak with someone at erwin about SQL, NoSQL or NewSQL in more detail, click here.
For more industry advice, subscribe to the erwin Expert Blog.
![]()
![]()