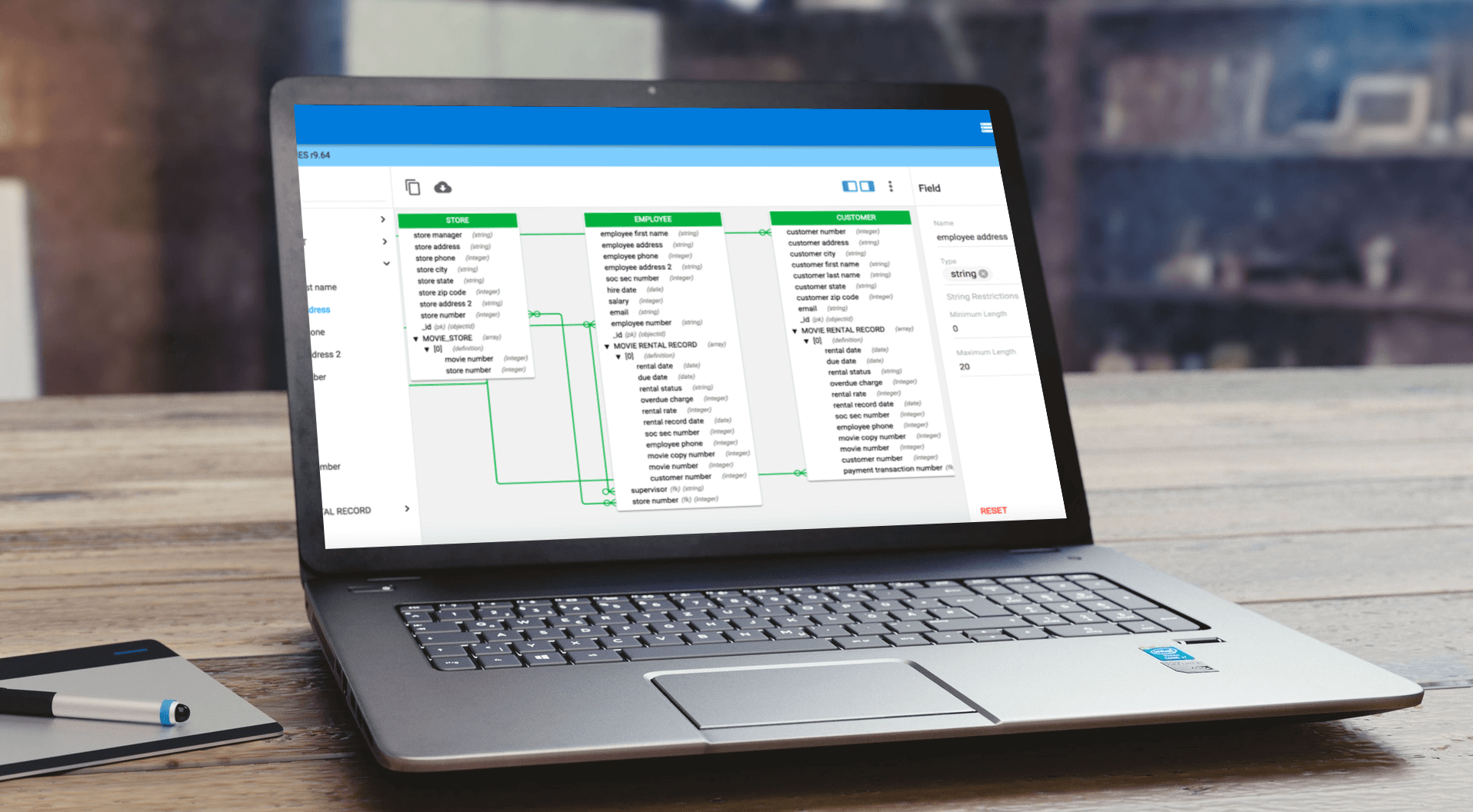
Organization’s cannot hope to make the most out of a data-driven strategy, without at least some degree of metadata-driven automation.
The volume and variety of data has snowballed, and so has its velocity. As such, traditional – and mostly manual – processes associated with data management and data governance have broken down. They are time-consuming and prone to human error, making compliance, innovation and transformation initiatives more complicated, which is less than ideal in the information age.
So it’s safe to say that organizations can’t reap the rewards of their data without automation.
Data scientists and other data professionals can spend up to 80 percent of their time bogged down trying to understand source data or addressing errors and inconsistencies.
That’s time needed and better used for data analysis.
By implementing metadata-driven automation, organizations across industry can unleash the talents of their highly skilled, well paid data pros to focus on finding the goods: actionable insights that will fuel the business.
![]()
![]()

Metadata-Driven Automation in the BFSI Industry
The banking, financial services and insurance industry typically deals with higher data velocity and tighter regulations than most. This bureaucracy is rife with data management bottlenecks.
These bottlenecks are only made worse when organizations attempt to get by with systems and tools that are not purpose-built.
For example, manually managing data mappings for the enterprise data warehouse via MS Excel spreadsheets had become cumbersome and unsustainable for one BSFI company.
After embracing metadata-driven automation and custom code automation templates, it saved hundreds of thousands of dollars in code generation and development costs and achieved more work in less time with fewer resources. ROI on the automation solutions was realized within the first year.
Metadata-Driven Automation in the Pharmaceutical Industry
Despite its shortcomings, the Excel spreadsheet method for managing data mappings is common within many industries.
But with the amount of data organizations need to process in today’s business climate, this manual approach makes change management and determining end-to-end lineage a significant and time-consuming challenge.
One global pharmaceutical giant headquartered in the United States experienced such issues until it adopted metadata-driven automation. Then the pharma company was able to scan in all source and target system metadata and maintain it within a single repository. Users now view end-to-end data lineage from the source layer to the reporting layer within seconds.
On the whole, the implementation resulted in extraordinary time savings and a total cost reduction of 60 percent.
Metadata-Driven Automation in the Insurance Industry
Insurance is another industry that has to cope with high data velocity and stringent data regulations. Plus many organizations in this sector find that they’ve outgrown their systems.
For example, an insurance company using a CDMA product to centralize data mappings is probably missing certain critical features, such as versioning, impact analysis and lineage, which adds to costs, times to market and errors.
By adopting metadata-driven automation, organizations can standardize the pre-ETL data mapping process and better manage data integration through the change and release process. As a result, both internal data mapping and cross functional teams now have easy and fast web-based access to data mappings and valuable information like impact analysis and lineage.
Here is the story of a business that adopted such an approach and achieved operational excellence and a delivery time reduction by 80 percent, as well as achieving ROI within 12 months.
Metadata-Driven Automation for a Non-Profit
Another common issue cited by organizations using manual data mapping is ballooning complexity and subsequent confusion.
Any organization expanding its data-driven focus without sufficiently maturing data management initiative(s) will experience this at some point.
One of the world’s largest humanitarian organizations, with millions of members and volunteers operating all over the world, was confronted with this exact issue.
It recognized the need for a solution to standardize the pre-ETL data mapping process to make data integration more efficient and cost-effective.
With metadata-driven automation, the organization would be able to scan and store metadata and data dictionaries in a central repository, as well as manage the business definitions and data dictionary for legacy systems contributing data to the enterprise data warehouse.
By adopting such an approach, the organization realized time savings across all IT development and cross-functional testing teams. Additionally, they were able to more easily manage mappings, code sets, reference data and data validation rules.
Again, ROI was achieved within a year.
A Universal Solution for Metadata-Driven Automation
Metadata-driven automation is a capability any organization can benefit from – regardless of industry, as demonstrated by the various real-world use cases chronicled here.
The erwin Automation Framework is a key component of the erwin EDGE platform for comprehensive data management and data governance.
With it, data professionals realize these industry-agnostic benefits:
- Centralized and standardized code management with all automation templates stored in a governed repository
- Better quality code and minimized rework
- Business-driven data movement and transformation specifications
- Superior data movement job designs based on best practices
- Greater agility and faster time-to-value in data preparation, deployment and governance
- Cross-platform support of scripting languages and data movement technologies
Learn more about metadata-driven automation as it relates to data preparation and enterprise data mapping.
Join one our weekly erwin Mapping Manager demos.
![]()
![]()