Happy Halloween!
Do you know where your data is? What data you have? Who has had access to it?
These can be frightening questions for an organization to answer.
Add to the mix the potential for a data breach followed by non-compliance, reputational damage and financial penalties and a real horror story could unfold.
In fact, we’ve seen some frightening ones play out already:
- Google’s record GDPR fine – France’s data privacy enforcement agency hit the tech giant with a $57 million penalty in early 2019 – more than 80 times the steepest fine the U.K.’s Information Commissioner’s Office had levied against both Facebook and Equifax for their data breaches.
- In July 2019, British Airways received the biggest GDPR fine to date ($229 million) because the data of more than 500,000 customers was compromised.
- Marriot International was fined $123 million, or 1.5 percent of its global annual revenue, because 330 million hotel guests were affected by a breach in 2018.
Now, as Cybersecurity Awareness Month comes to a close – and ghosts and goblins roam the streets – we thought it a good time to resurrect some guidance on how data governance can make data security less scary.
We don’t want you to be caught off guard when it comes to protecting sensitive data and staying compliant with data regulations.
![]()
![]()

Don’t Scream; You Can Protect Your Sensitive Data
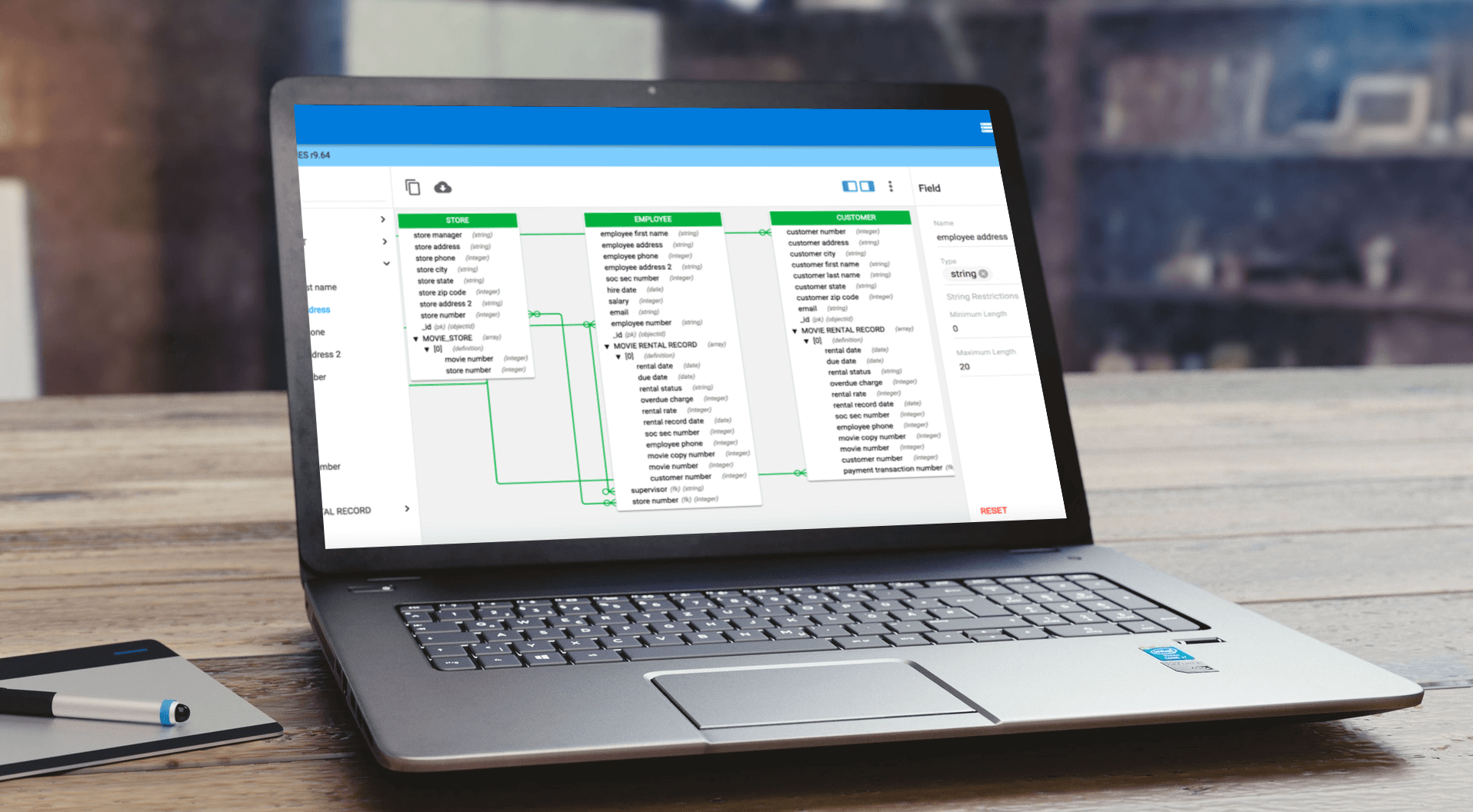
It’s easier to protect sensitive data when you know what it is, where it’s stored and how it needs to be governed.
Data security incidents may be the result of not having a true data governance foundation that makes it possible to understand the context of data – what assets exist and where, the relationship between them and enterprise systems and processes, and how and by what authorized parties data is used.
That knowledge is critical to supporting efforts to keep relevant data secure and private.
Without data governance, organizations don’t have visibility of the full data landscape – linkages, processes, people and so on – to propel more context-sensitive security architectures that can better assure expectations around user and corporate data privacy. In sum, they lack the ability to connect the dots across governance, security and privacy – and to act accordingly.
This addresses these fundamental questions:
- What private data do we store and how is it used?
- Who has access and permissions to the data?
- What data do we have and where is it?
Where Are the Skeletons?
Data is a critical asset used to operate, manage and grow a business. While sometimes at rest in databases, data lakes and data warehouses; a large percentage is federated and integrated across the enterprise, introducing governance, manageability and risk issues that must be managed.
Knowing where sensitive data is located and properly governing it with policy rules, impact analysis and lineage views is critical for risk management, data audits and regulatory compliance.
However, when key data isn’t discovered, harvested, cataloged, defined and standardized as part of integration processes, audits may be flawed and therefore your organization is at risk.
Sensitive data – at rest or in motion – that exists in various forms across multiple systems must be automatically tagged, its lineage automatically documented, and its flows depicted so that it is easily found and its usage across workflows easily traced.
Thankfully, tools are available to help automate the scanning, detection and tagging of sensitive data by:
- Monitoring and controlling sensitive data: Better visibility and control across the enterprise to identify data security threats and reduce associated risks
- Enriching business data elements for sensitive data discovery: Comprehensively defining business data element for PII, PHI and PCI across database systems, cloud and Big Data stores to easily identify sensitive data based on a set of algorithms and data patterns
- Providing metadata and value-based analysis: Discovery and classification of sensitive data based on metadata and data value patterns and algorithms. Organizations can define business data elements and rules to identify and locate sensitive data including PII, PHI, PCI and other sensitive information.
No Hocus Pocus
Truly understanding an organization’s data, including its value and quality, requires a harmonized approach embedded in business processes and enterprise architecture.
Such an integrated enterprise data governance experience helps organizations understand what data they have, where it is, where it came from, its value, its quality and how it’s used and accessed by people and applications.
An ounce of prevention is worth a pound of cure – from the painstaking process of identifying what happened and why to notifying customers their data and thus their trust in your organization has been compromised.
A well-formed security architecture that is driven by and aligned by data intelligence is your best defense. However, if there is nefarious intent, a hacker will find a way. So being prepared means you can minimize your risk exposure and the damage to your reputation.
Multiple components must be considered to effectively support a data governance, security and privacy trinity. They are:
- Data models
- Enterprise architecture
- Business process models
Creating policies for data handling and accountability and driving culture change so people understand how to properly work with data are two important components of a data governance initiative, as is the technology for proactively managing data assets.
Without the ability to harvest metadata schemas and business terms; analyze data attributes and relationships; impose structure on definitions; and view all data in one place according to each user’s role within the enterprise, businesses will be hard pressed to stay in step with governance standards and best practices around security and privacy.
As a consequence, the private information held within organizations will continue to be at risk.
Organizations suffering data breaches will be deprived of the benefits they had hoped to realize from the money spent on security technologies and the time invested in developing data privacy classifications.
They also may face heavy fines and other financial, not to mention PR, penalties.
- You can learn more by reading our whitepaper: Examining the Data Trinity: Governance, Security and Privacy.
![]()
![]()