There’s no escaping data’s role in the cloud, and so it’s crucial that we analyze the cloud’s impact on data modeling.
Tag: adrm
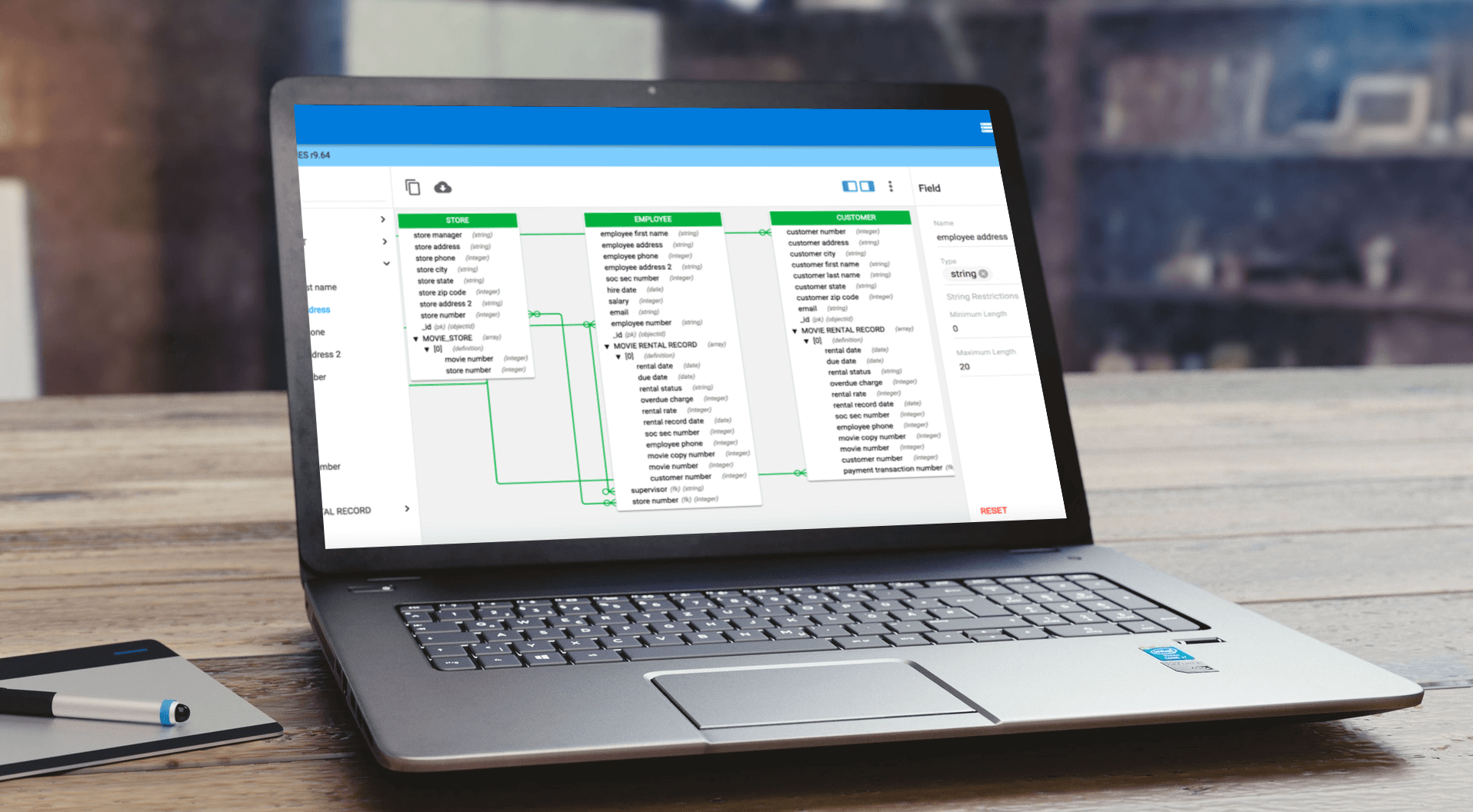
In the first two posts of this series, we focused on the “volume” and “velocity” of Big Data, respectively. In this post, we’ll cover “variety,” the third of Big Data’s “three Vs.” In particular, I plan to discuss NoSQL and NewSQL databases and their implications for data modeling.
As the volume and velocity of data available to organizations continues to rapidly increase, developers have chafed under the performance shackles of traditional relational databases and SQL.
An astonishing array of database solutions have arisen during the past decade to provide developers with higher performance solutions for various aspects of managing their application data. These have been collectively labeled as NoSQL databases.
Originally NoSQL meant that “no SQL” was required to interface with the database. In many cases, developers viewed this as a positive characteristic.
However, SQL is very useful for some tasks, with many organizations having rich SQL skillsets. Consequently, as more organizations demanded SQL as an option to complement some of the new NoSQL databases, the term NoSQL evolved to mean “not only SQL.” This way, SQL capabilities can be leveraged alongside other non-traditional characteristics.
Among the most popular of these new NoSQL options are document databases like MongoDB. MongoDB offers the flexibility to vary fields from document to document and change structure over time. Document databases typically store data in JSON-like documents, making it easy to map to objects in application code.
As the scale of NoSQL deployments in some organizations has rapidly grown, it has become increasingly important to have access to enterprise-grade tools to support modeling and management of NoSQL databases and to incorporate such databases into the broader enterprise data modeling and governance fold.
While document databases, key-value databases, graph databases and other types of NoSQL databases have added valuable options for developers to address various challenges posed by the “three Vs,” they did so largely by compromising consistency in favor of availability and speed, instead offering “eventual consistency.” Consequently, most NoSQL stores lack true ACID transactions, though there are exceptions, such as Aerospike and MarkLogic.
But some organizations are unwilling or unable to forgo consistency and transactional requirements, giving rise to a new class of modern relational database management systems (RDBMS) that aim to guarantee ACIDity while also providing the same level of scalability and performance offered by NoSQL databases.
NewSQL databases are typically designed to operate using a shared nothing architecture. VoltDB is one prominent example of this emerging class of ACID-compliant NewSQL RDBMS. The logical design for NewSQL database schemas is similar to traditional RDBMS schema design, and thus, they are well supported by popular enterprise-grade data modeling tools such as erwin DM.
Whatever mixture of databases your organization chooses to deploy for your OLTP requirements on premise and in the cloud – RDBMS, NoSQL and/or NewSQL – it’s as important as ever for data-driven organizations to be able to model their data and incorporate it into an overall architecture.
When it comes to organizations’ analytics requirements, including data that may be sourced from a wide range of NoSQL, NewSQL RDBMS and unstructured sources, leading organizations are adopting a variety of approaches, including a hybrid approach that many refer to as Managed Data Lakes.
Please join us next time for the fourth installment in our series: Data Modeling in a Jargon-filled World – Managed Data Lakes.
![]()
![]()

In the first post of this blog series, we focused on jargon related to the “volume” aspect of Big Data and its impact on data modeling and data-driven organizations. In this post, we’ll focus on “velocity,” the second of Big Data’s “three Vs.”
In particular, we’re going to explore the Internet of Things (IoT), the constellation of web-connected devices, vehicles, buildings and related sensors and software. It’s a great time for this discussion too, as IoT devices are proliferating at a dizzying pace in both number and variety.
Though IoT devices typically generate small “chunks” of data, they often do so at a rapid pace, hence the term “velocity.” Some of these devices generate data from multiple sensors for each time increment. For example, we recently worked with a utility that embedded sensors in each transformer in its electric network and then generated readings every 4 seconds for voltage, oil pressure and ambient temperature, among others.
While the transformer example is just one of many, we can quickly see two key issues that arise when IoT devices are generating data at high velocity. First, organizations need to be able to process this data at high speed. Second, organizations need a strategy to manage and integrate this never-ending data stream. Even small chunks of data will accumulate into large volumes if they arrive fast enough, which is why it’s so important for businesses to have a strong data management platform.
It’s worth noting that the idea of managing readings from network-connected devices is not new. In industries like utilities, petroleum and manufacturing, organizations have used SCADA systems for years, both to receive data from instrumented devices to help control processes and to provide graphical representations and some limited reporting.
More recently, many utilities have introduced smart meters in their electricity, gas and/or water networks to make the collection of meter data easier and more efficient for a utility company, as well as to make the information more readily available to customers and other stakeholders.
For example, you may have seen an energy usage dashboard provided by your local electric utility, allowing customers to view graphs depicting their electricity consumption by month, day or hour, enabling each customer to make informed decisions about overall energy use.
Seems simple and useful, but have you stopped to think about the volume of data underlying this feature? Even if your utility only presents information on an hourly basis, if you consider that it’s helpful to see trends over time and you assume that a utility with 1.5 million customers decides to keep these individual hourly readings for 13 months for each customer, then we’re already talking about over 14 billion individual readings for this simple example (1.5 million customers x 13 months x over 30 days/month x 24 hours/day).
Now consider the earlier example I mentioned of each transformer in an electrical grid with sensors generating multiple readings every 4 seconds. You can get a sense of the cumulative volume impact of even very small chunks of data arriving at high speed.
With experts estimating the IoT will consist of almost 50 billion devices by 2020, businesses across every industry must prepare to deal with IoT data.
But I have good news because IoT data is generally very simple and easy to model. Each connected device typically sends one or more data streams with each having a value for the type of reading and the time at which it occurred. Historically, large volumes of simple sensor data like this were best stored in time-series databases like the very popular PI System from OSIsoft.
While this continues to be true for many applications, alternative architectures, such as storing the raw sensor readings in a data lake, are also being successfully implemented. Though organizations need to carefully consider the pros and cons of home-grown infrastructure versus time-tested industrial-grade solutions like the PI System.
Regardless of how raw IoT data is stored once captured, the real value of IoT for most organizations is only realized when IoT data is “contextualized,” meaning it is modeled in the context of the broader organization.
The value of modeled data eclipses that of “edge analytics” (where the value is inspected by a software program while inflight from the sensor, typically to see if it falls within an expected range, and either acted upon if required or allowed simply to pass through) or simple reporting like that in the energy usage dashboard example.
It is straightforward to represent a reading of a particular type from a particular sensor or device in a data model or process model. It starts to get interesting when we take it to the next step and incorporate entities into the data model to represent expected ranges – both for readings under various conditions and representations of how the devices relate to one another.
If the utility in the transformer example has modeled that IoT data well, it might be able to prevent a developing problem with a transformer and also possibly identify alternate electricity paths to isolate the problem before it has an impact on network stability and customer service.
Hopefully this overview of IoT in the utility industry helps you see how your organization can incorporate high-velocity IoT data to become more data-driven and therefore more successful in achieving larger corporate objectives.
Subscribe and join us next time for Data Modeling in a Jargon-filled World – NoSQL/NewSQL.
![]()
![]()
