![]()
![]()

Due to the prevalence of internal and external market disruptors, many organizations are aligning their digital transformation and cloud migration efforts with other strategic requirements (e.g., compliance with the General Data Protection Regulation).
Accelerating the retrieval and analysis of data —so much of it unstructured—is vital to becoming a data-driven business that can effectively respond in real time to customers, partners, suppliers and other parties, and profit from these efforts. But even though speed is critical, businesses must take the time to model and document new applications for compliance and transparency.
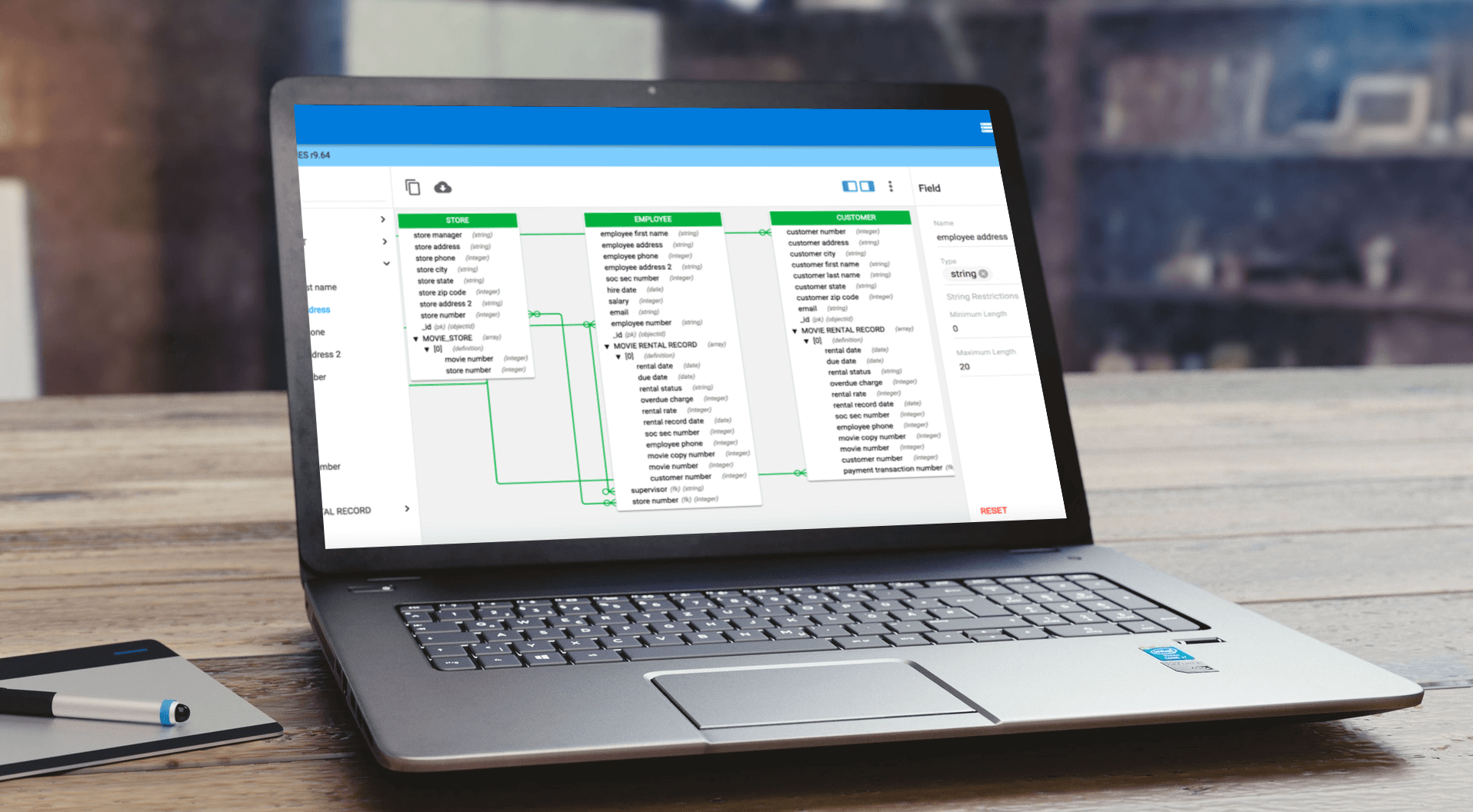
For decades, data modeling has been the optimal way to design and deploy new relational databases with high-quality data sources and support application development. It facilitates communication between the business and system developers so stakeholders can understand the structure and meaning of enterprise data within a given context. Today, it provides even greater value because critical data exists in both structured and unstructured formats and lives both on premises and in the cloud.
Comparing SQL and NoSQL
While it may not be the most exciting match up, there’s much to be said when comparing SQL vs NoSQL databases. SQL databases use schemas and pre-defined tables, while NoSQL databases are the complete opposite. Instead of schemas and tables, NoSQL databases store data in ways that depend on what kind of NoSQL database is being used.
While the SQL and NoSQL worlds can complement each other in today’s data ecosystem, most enterprises need to focus on building expertise and processes for the latter format.
After all, they’ve already had decades of practice designing and managing SQL databases that emphasize storage efficiency and referential integrity rather than fast data access, which is so important to building cloud applications that deliver real-time value to staff, customers and other parties. Query-optimized modeling is the new watchword when it comes to supporting today’s fast delivery, iterative and real-time applications
DBMS products based on rigid schema requirements impede our ability to fully realize business opportunities that can expand the depth and breadth of relevant data streams for conversion into actionable information. New, business-transforming use cases often involve variable data feeds, real-time or near-time processing and analytics requirements, and the scale to process large volumes of data.
NoSQL databases, such as Couchbase and MongoDB, are purpose-built to handle the variety, velocity and volume of these new data use cases. Schema-less or dynamic schema capabilities, combined with increased processing speed and built-in scalability, make NoSQL the ideal platform.
Making the Move to NoSQL
Now the hard part. Once we’ve agreed to make the move to NoSQL, the next step is to identify the architectural and technological implications facing the folks tasked with building and maintaining these new mission-critical data sources and the applications they feed.
As the data modeling industry leader, erwin has identified a critical success factor for the majority of organizations adopting a NoSQL platform like Couchbase, Cassandra and MongoDB. Successfully leveraging this solution requires a significant paradigm shift in how we design NoSQL data structures and deploy the databases that manage them.
But as with most technology requirements, we need to shield the business from the complexity and risk associated with this new approach. The business cares little for the technical distinctions of the underlying data management “black box.”
Business data is business data, with the main concerns being its veracity and value. Accountability, transparency, quality and reusability are required, regardless. Data needs to be trusted, so decisions can be made with confidence, based on facts. We need to embrace this paradigm shift, while ensuring it fits seamlessly into our existing data management practices as well as interactions with our partners within the business. Therefore, the challenge of adopting NoSQL in an organization is two-fold: 1) mastering and managing this new technology and 2) integrating it into an expansive and complex infrastructure.
The Newest Release of erwin Data Modeler
There’s a reason erwin Data Modeler is the No.1 data modeling solution in the world.
And the newest release delivers all in one SQL and NoSQL data modeling, guided denormalization and model-driven engineering support for Couchbase, Cassandra, MongoDB, JSON and AVRO. NoSQL users get all of the great capabilities inherent in erwin Data Modeler. It also provides Data Vault modeling, enhanced productivity, and simplified administration of the data modeling repository.
Now you can rely on one solution for all your enterprise data modeling needs, working across DBMS platforms, using modern modeling techniques for faster data value, and centrally governing all data definition, data modeling and database design initiatives.
erwin data models reduce complexity, making it easier to design, deploy and understand data sources to meet business needs. erwin Data Modeler also automates and standardizes model design tasks, including complex queries, to improve business alignment, ensure data integrity and simplify integration.
In addition to the above, the newest release of erwin Data Modeler by Quest also provides:
- Updated support and certifications for the latest versions of Oracle, MS SQL Server, MS Azure SQL and MS Azure SQL Synapse
- JDBC-connectivity options for Oracle, MS SQL Server, MS Azure SQL, Snowflake, Couchbase, Cassandra and MongoDB
- Enhanced administration capabilities to simplify and accelerate data model access, collaboration, governance and reuse
- New automation, connectivity, UI and workflow optimization to enhance data modeler productivity by reducing onerous manual tasks
erwin Data Modeler is a proven technology for improving the quality and agility of an organization’s overall data capability – and that includes data governance and data intelligence.
Click here for your free trial of erwin Data Modeler.