Digital trust can make or break a brand.
Amazon understood this concept early on. When the company first launched as an online bookseller in 1994, consumer confidence in online shopping was low, to say the least.
Exclusively competing with local bookstores, Amazon and many e-tailers throughout the 90s and early 2000s had to work to create trust in online shopping. Their efforts paid off, ushering in a new era and transforming the way we all shop today.
Amazon is a good example of digital trust making a brand. But data breaches are a telling metric of how lack of digital trust can break a brand.
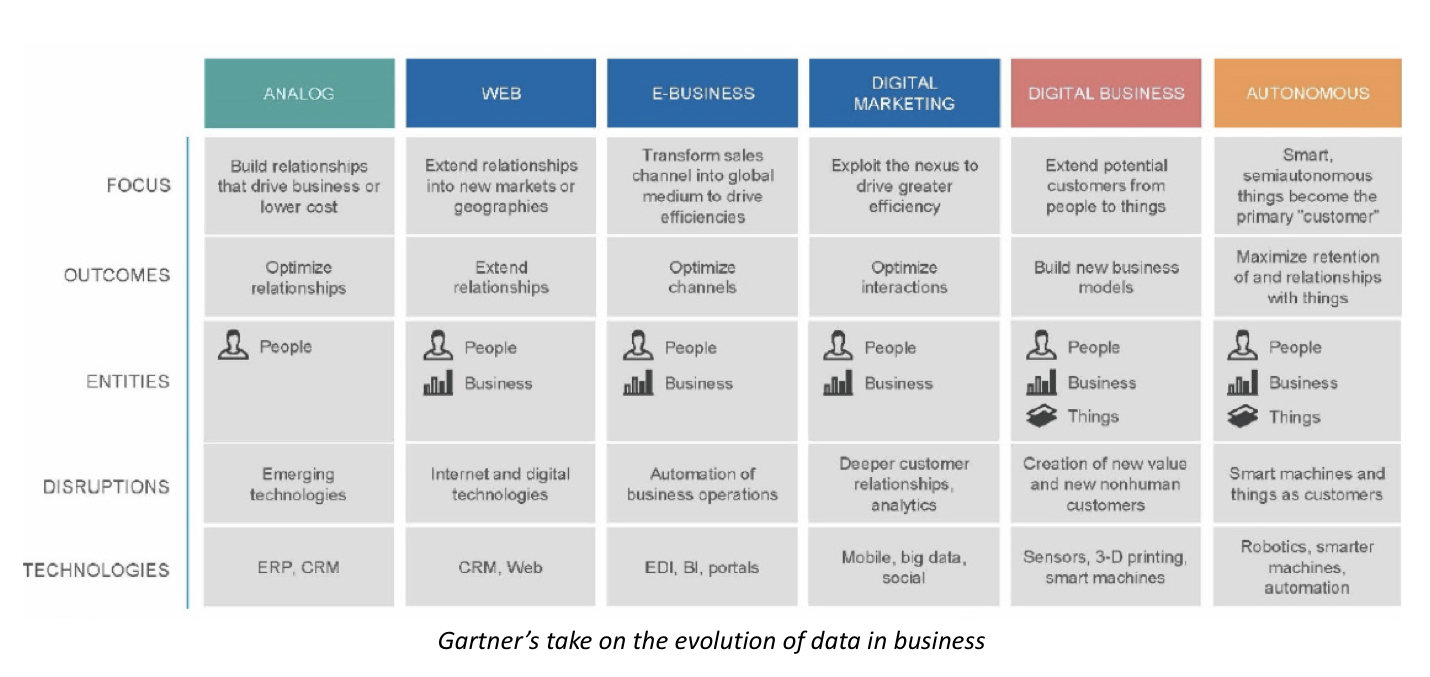
Frequency of Data Breaches and Its Impact on Consumer Trust
Since Privacy Rights Clearinghouse began tracking data breaches in 2005, 7,731 have been reported, with an estimated 1 billion individual records breached. And that estimate is conservative. While a data breach may have been reported, the number of individual records involved isn’t always known.
The Ponemon Institute’s 2017 Cost of Data Breach Study suggests the odds of suffering a data breach within the year are as high as one in four. As if the growing number of data breaches isn’t enough to contend with, considerable evidence suggests their impact is increasing too.
Although the Ponemon Institute study found the financial cost of a data breach fell by 10 percent between 2016 and 2017, the “financial cost” doesn’t account for the various intangible effects of a data breach that can, and do, add up.
For example, the reputational cost more than likely outweighs the clean-up costs of a high-profile data breach like the one Equifax suffered recently. That incident is believed to have reduced Equifax’s market value by $3 billion, as share prices tumbled by as much as 17 percent.
In fact, any company disclosing a data breach saw its average stock price fall by 5 percent, according to Ponemon. And 21 percent of consumers included in its study reported ending their relationships with a company that had been breached. Why? They lost trust in those businesses.
Perhaps the most relevant finding here is that “organizations with a poor security posture experienced an increase of up to 7 percent customer churn, which can amount to millions in lost revenue.” Clearly this shows the correlation between digital trust and customer retention. It also demonstrates that the consumer is aware of such matters.
That’s why digital trust poses an opportunity. Yes, consumer trust is declining. Yes, high-profile breaches are increasing. But these are alarm bells, not death knells.
Businesses can use the issue of digital trust to their advantage. By making it a unique value proposition reinforced by a solid data governance (DG) program, you can set yourself apart from the competition – not to mention avoid GDPR penalties.
![]()
![]()

Building Digital Trust Through Data Governance
In today’s digital economy, the consumer holds the power with more avenues of research and reviews to inform purchase decisions. Even in the B2B world, studies indicate that 47 percent of buyers view three to five pieces of content before engaging with a sales rep.
In other words, the consumer is clued in. But if a data breach occurs, it doesn’t have to lead to customer losses. It could actually reinforce customer loyalty and produce an uptick in new customers – if you are proactive in your response and transparent about your procedures for data governance.
Of course, consumer trust isn’t built overnight. It’s a process, influenced by sound data governance practices and routine demonstrations of said practices so trust becomes part of your brand.
While considering the long-term payoff, it’s also worth noting the advantages a data governance program has in the short-term. For better or worse, short-term positive outcomes are what business leaders and decision- makers want to see.
When it comes to both digital trust and business outcomes, DG’s biggest advantage is ensuring an organization can first trust its own data.
In addition to helping an organization discover, understand and then socialize its mission-critical information for greater visibility, it also improves the enterprise’s ability to govern and control data. You literally get a handle on how you handle your data – and not just to help prevent breaches.
Greater certainty around the quality of data leads to faster and more productive decision-making. It reduces the risk of misleading models, analysis and prediction, meaning less time, money and other resources are wasted.
Additionally, the very data used in such models and analysis benefits from improved clarity. Meaning what’s relevant is more readily discoverable, speeding up the entire strategic planning and decision-making process.
So, proactive and proficient data governance doesn’t just mitigate risk, it fundamentally improves operational performance and accelerates growth.
For more data best practices click here, and you can stay up to date with our latest posts here.
![]()
![]()